
Давай рассмотрим как управляют памятью два популярных языка программирования - Rust и Go.
Когда запускается программа, создается процесс с собственным адресным пространством и потоками, выполняющимися на ядрах. Процессор работает с виртуальной памятью - абстракцией, которой управляет операционная система.
Например в Go, когда мы создаем массив:
arr := make([]byte, 100)рантайм запрашивает диапазон виртуальных адресов, но физическая память выделяется не сразу, а при первом обращении к данным:
first := arr[0]Запрашивая первый элемент происходит page fault и операционная система выделяет физическую страницу, обычно 4kb, связывая ее с виртуальным диапазоном.
Стэк и куча
В каждом процессе есть общий диапазон памяти, доступный всем потокам, который называется куча - heap.
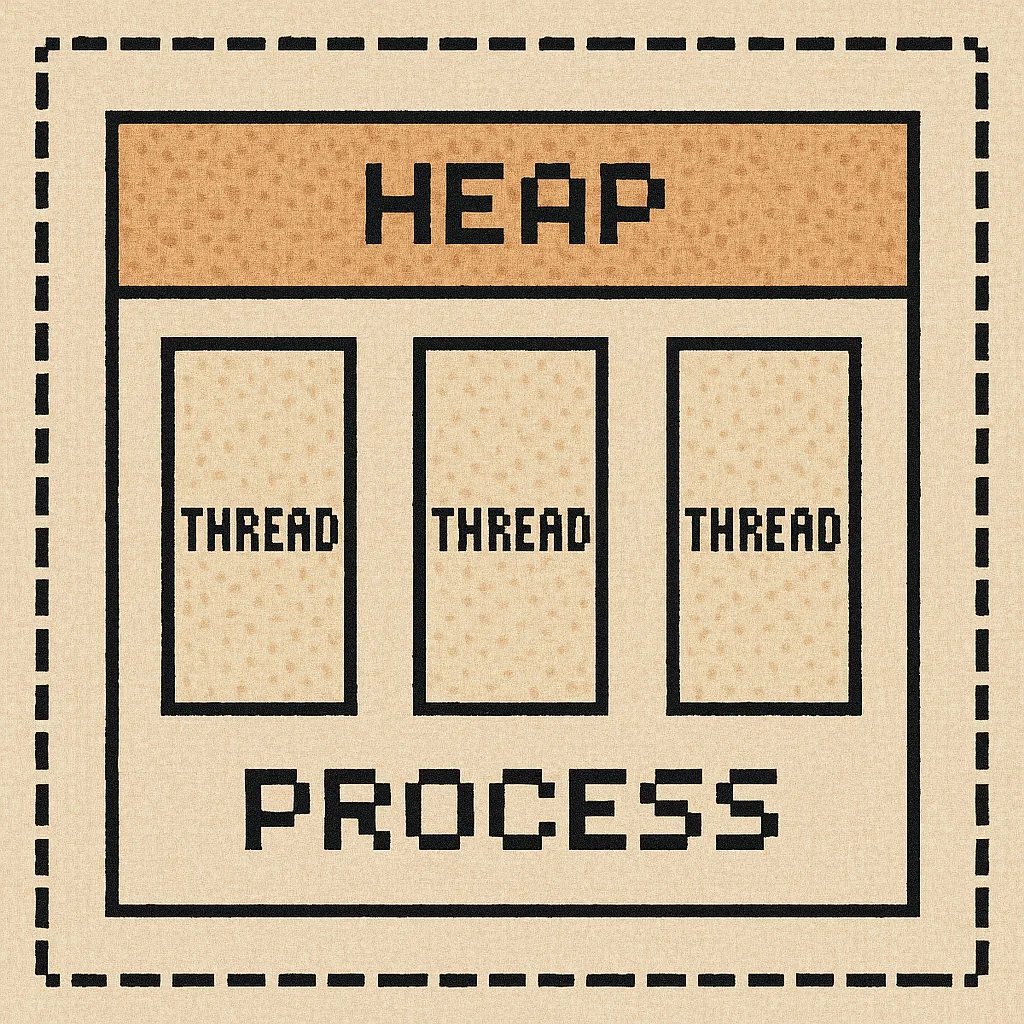
С этой областью памяти может работать любой поток, и эта область может динамически расширяться во время работы программы.
При этом в каждом потоке есть своя область памяти, с которой может работать только сам поток, которая называется стек - stack.
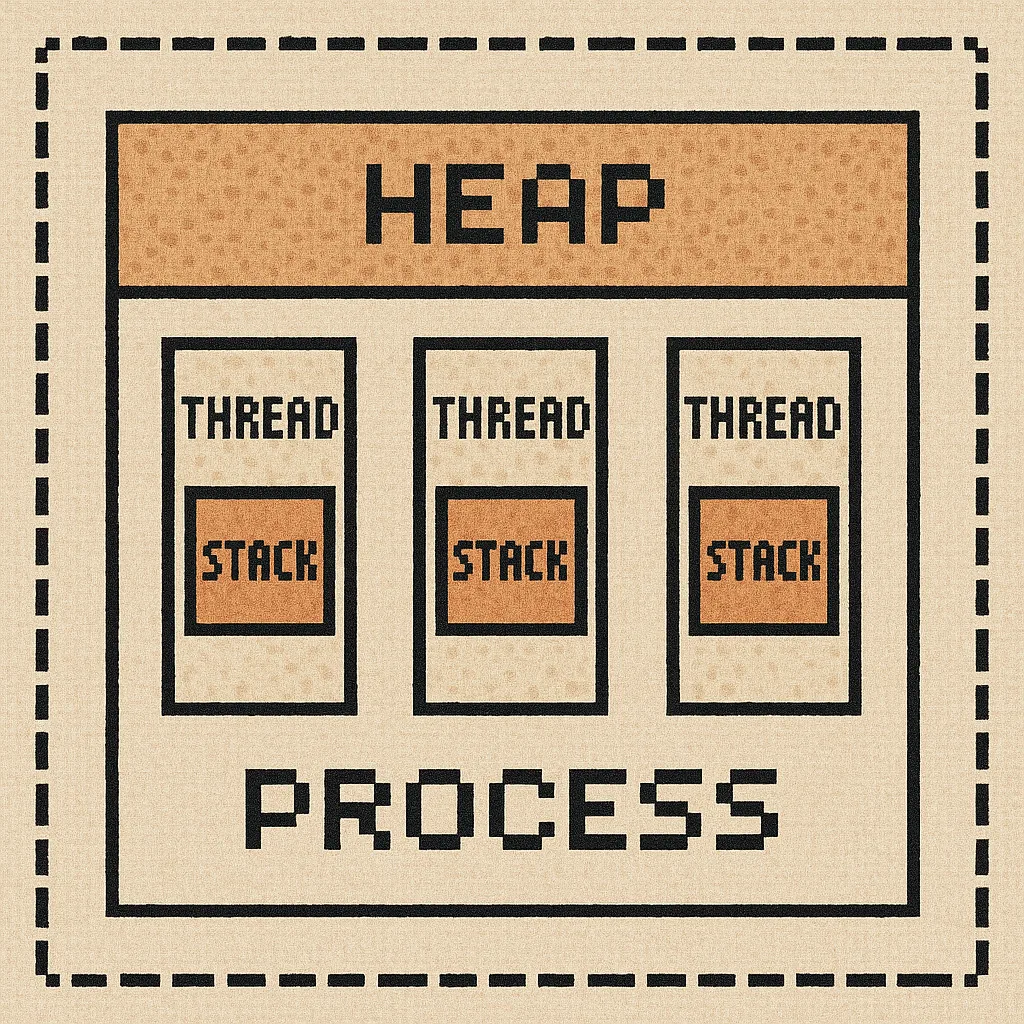
На стеке хранятся:
локальные переменные примитивных типов
аргументы функций
адреса возврата (место, откуда была вызвана функция и куда должно вернуться выполнение после ее завершения)
Все эти данные существуют до завершения функции, после чего стек очищается.
Как Go решает, где аллоцировать данные?
В Go решение о размещении принимает escape-анализатор - фаза работы компилятора, во время которой он принимает решение где будут храниться те или иные данные.
Например для этого кода:
func add(a, b int) int {
c := a + b
return c
}escape анализатор увидит, что переменная c живет в рамках функции (return c не возвращает участок памяти, где выделена c, а копирует ее значение в регистр возврата), значит - ее можно поместить на стек.
А в таком примере:
func newUser() *User {
u := User{Name: "Tom"}
return &u
}escape анализатор решит, что раз значение возвращается по указателю - область памяти должна жить после окончания функции, значит разместит u в куче.
Итого, в Go компилятор решает где будут лежать переменные, анализируя код.
Как Rust решает, где аллоцировать данные?
В Rust компилятор не выполняет escape-анализ и не решает сам, где хранить данные - это решает разработчик. Чтобы поместить объект в кучу, нужно явно использовать тип, который работает на куче, например Box:
let x = Box::new(5);Тип Box по определению гарантирует, что значение T хранится в куче. Затем, когда разработчик принял все решения, компилятор проверят их корректность через анализ владения и анализ времени жизни.
Анализ времени жизни
Во время этой фазы компилятор проверяет, что нет ссылок на объект, память под которым уже освобождена.
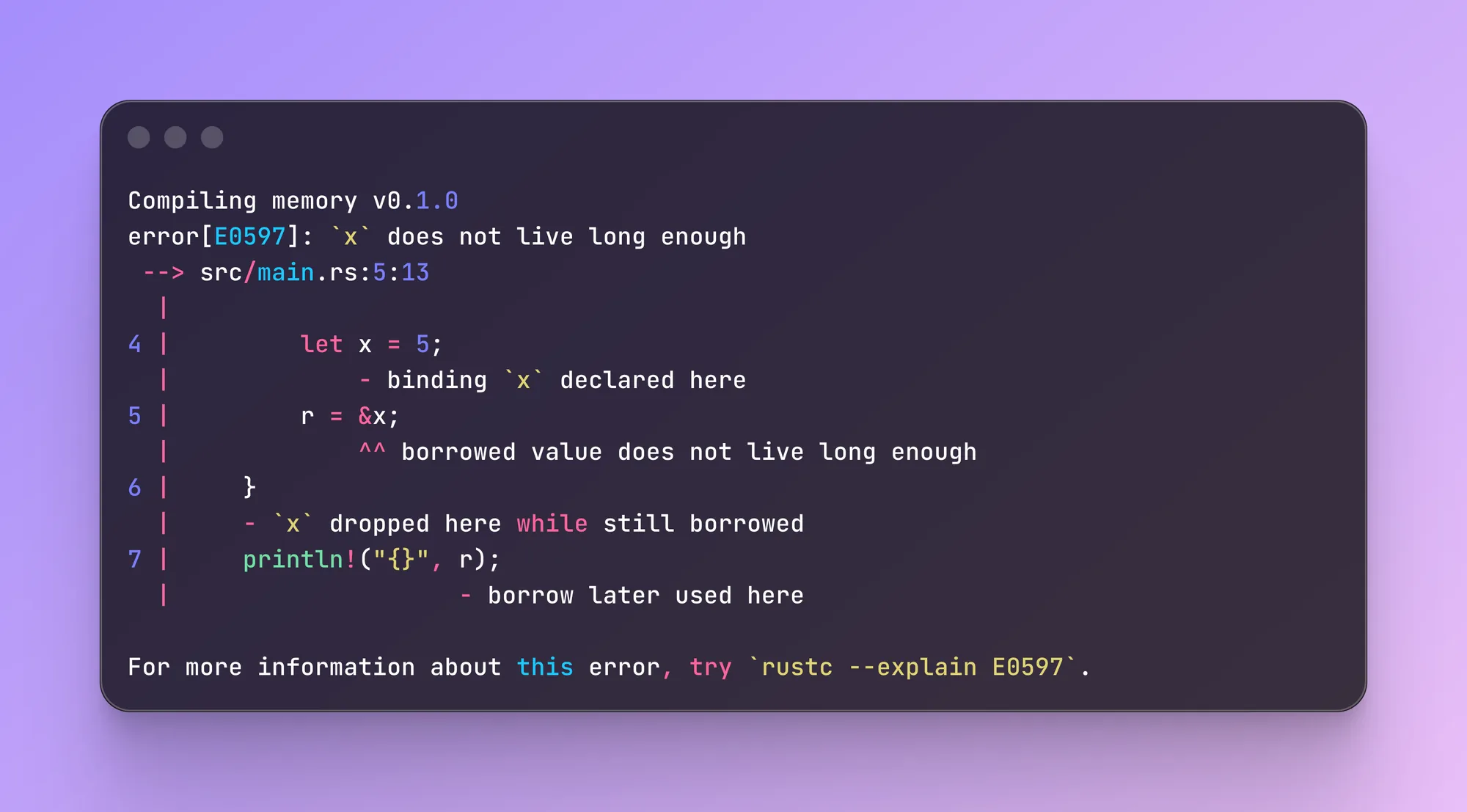
fn main() {
let r;
{
let x = 5;
r = &x; // error: x lives shorter than r
}
println!("{}", r);
}Например, в этом коде переменная x имеет меньшую область видимости, чем r, и компилятор вернет ошибку: r указывает на ячейку памяти, память под которую уже будет освобождена:
А в Go такой же пример скомпилируется без ошибок:
func main() {
var r *int
{
x := 5
r = &x
}
fmt.Println(*r)
}потому что escape-анализ понимает, что x утекает за пределы блока и принимает решение, что x должен жить дольше - значит размещаем его на куче.
Анализ владения
После фазы проверки времени жизни наступает фаза анализа владения. В Rust каждая переменная - владелец своих данных. Когда владелец данных выходит из области видимости, вызывается drop() и память освобождается. Владение гарантирует, что не произойдет утечек и двойного освобождения памяти.
fn main() {
let s = String::from("hello");
println!("{}", s);
} // drop() is called here and the memory for s is freedПравила владения следующие:
У одного ресурса всегда один владелец
При передаче владения старый владелец теряет доступ
Данные удаляются, когда владелец выходит из области видимости
Посмотрим на пример:
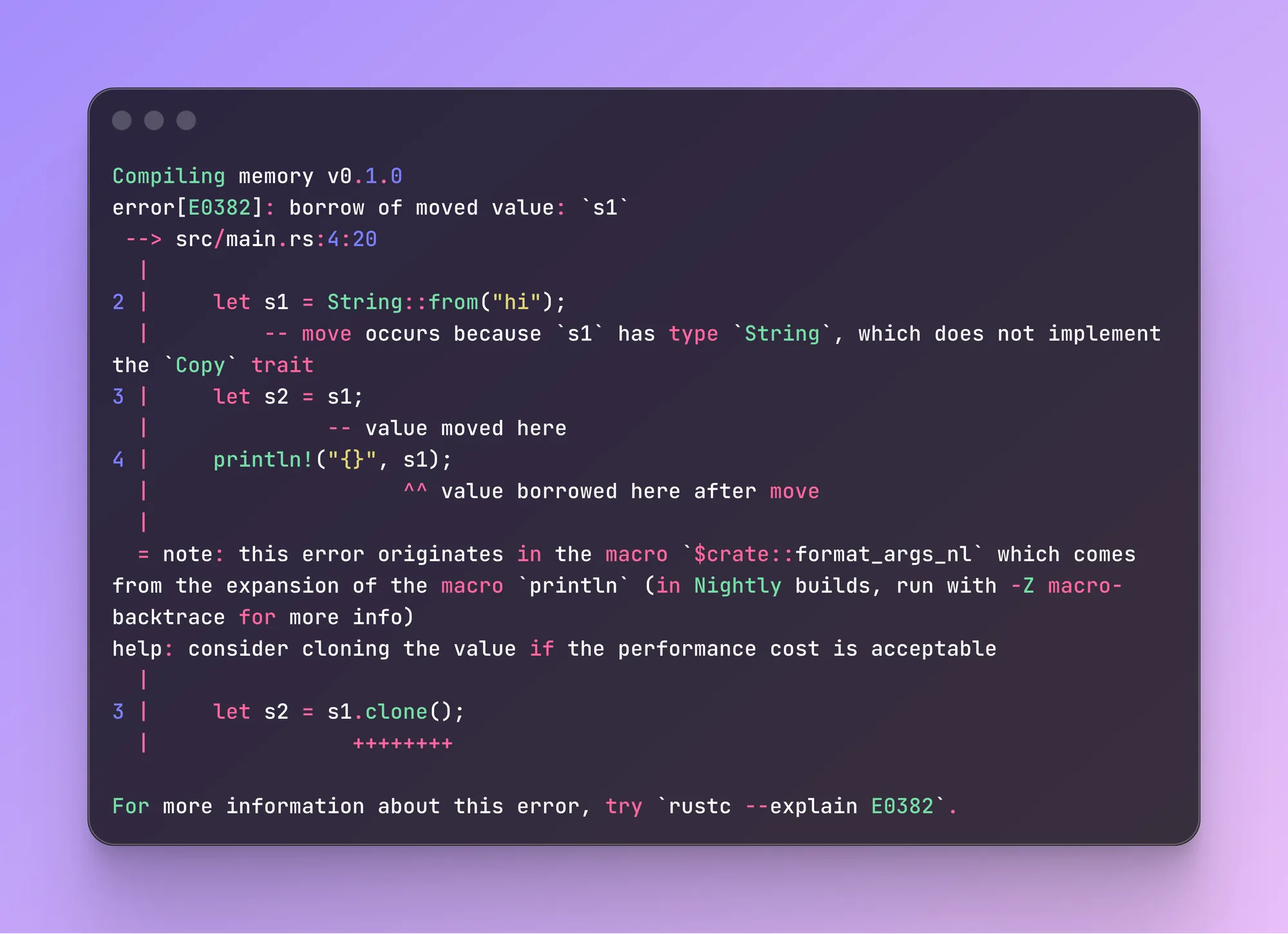
fn main() {
let s1 = String::from("hi");
let s2 = s1; // ownership is moved
println!("{}", s1); // error - s1 no longer owns the data
}Тут мы делаем перенос владельца, после чего пытаемся вывести на экран данные из предыдущего - компиляция заканчивается с ошибкой:
То же при передаче в функцию:
fn takes_ownership(s: String) { println("{}", s); }
fn main() {
let s = String::from("hi");
takes_ownership(s)
println!("{}", s); // error - s no longer owns the data
}Ошибка:

Если ты пишешь на Go, то пример выше - совсем неочевидный. Почему s не владеет данными, ведь внутри takes_ownership() данные просто выводятся на экран?
Потому что при передаче в функцию владение переходит к параметру s, когда она заканчивается - s уничтожается. Это гарантия того, что один и тот же ресурс не будет освобожден дважды.
Чтобы пример выше заработал - нам нужно передать значение по ссылке:
fn takes_ownership(s: &String) {
println!("{}", s);
}
fn main() {
let s = String::from("hi");
takes_ownership(&s)
println!("{}", s);
}Так Rust обеспечивает безопасность на этапе компиляции.
А почему Rust просто не перемещает объект со стека на кучу сам, как в Go?
Мы обсудили как происходит уборка мусора в Rust - контролем разработчика и ошибками от компилятора. Как это происходит в Go?
Тут на сцену выходит сборщик мусора - garbage collector. Сборщик мусора - рантайма языка, работающей параллельно с нашей программой. GC удаляет все объекты, под которые выделена память, но на которые никто не указывает.
Благодаря этому мы не заботимся о том, где будет храниться объект, но должны всегда помнить о том, что параллельно с нашей программой работает GC и тратит на это ресурсы процессора. Rust же тратит ресурсы только на выполнение кода, еще на фазе компиляции гарантируя, что все аллокации будут размещены в нужных местах и очищены в нужный момент.
Давай посмотрим на пример когда и на то, сколько ресурсов процессора тратят оба языка.
Ниже код на Go, выполняющий 1000000 аллокаций и сохраняющий часть из них в общий буффер:
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
"time"
)
var keep [][]byte // keep some buffers so there is "live" garbage
func main() {
// pprof endpoints on :6060
go func() {
fmt.Println("pprof on http://localhost:6060/debug/pprof/")
_ = http.ListenAndServe("localhost:6060", nil)
}()
// light CPU load + lots of allocations
go func() {
for i := 0; i < 1_000_000; i++ {
buf := make([]byte, 1024) // 1KB on the heap
if i%1000 == 0 { // keep some of them "alive"
keep = append(keep, buf)
}
if i%100_000 == 0 {
fmt.Println("iter", i)
time.Sleep(1000 * time.Millisecond)
}
}
fmt.Println("done, kept:", len(keep))
}()
select{}
}Go позволяет посмотреть, какие решения принимал escape анализ, для этого запускаем go build с флагом -m:
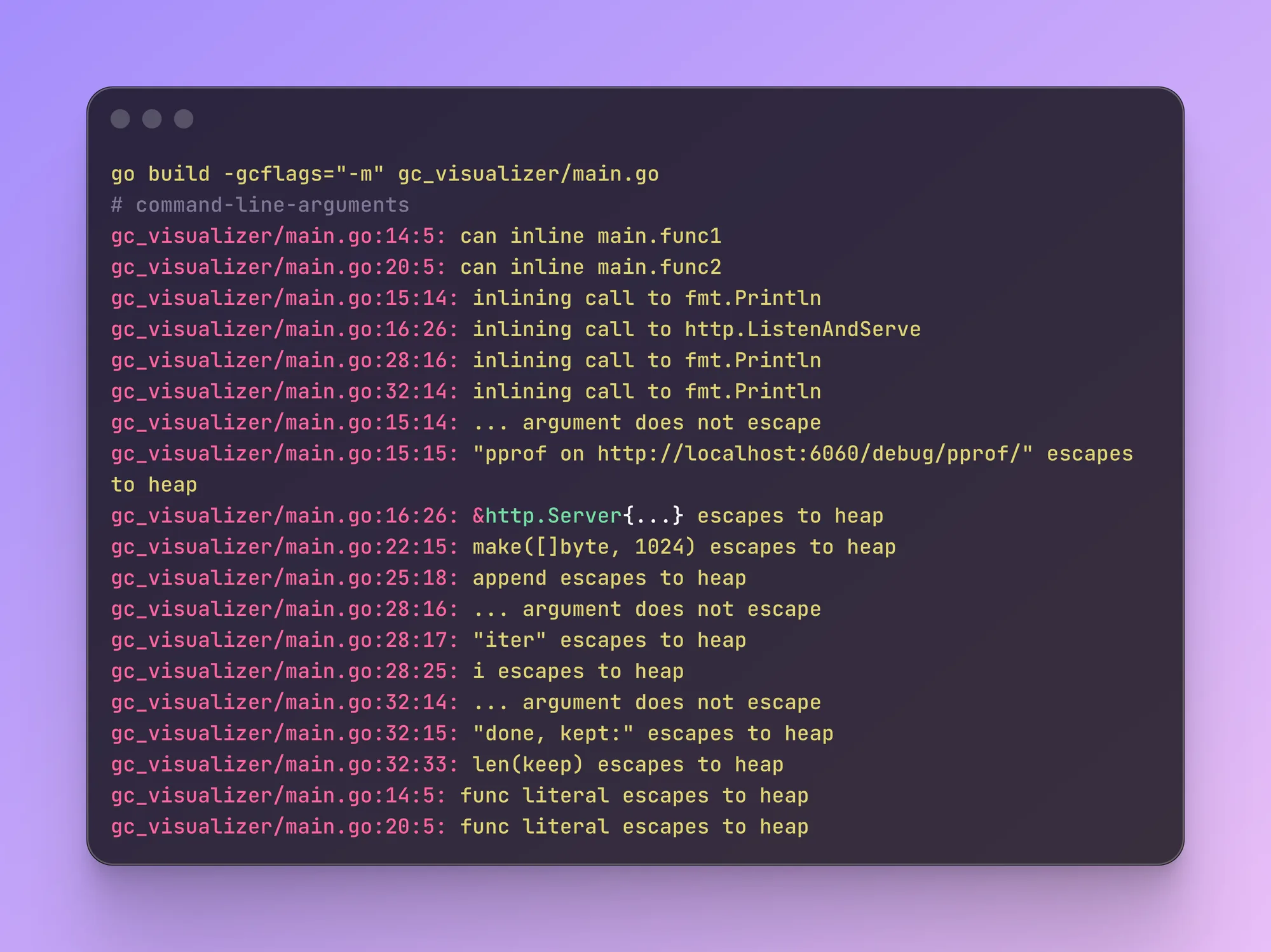
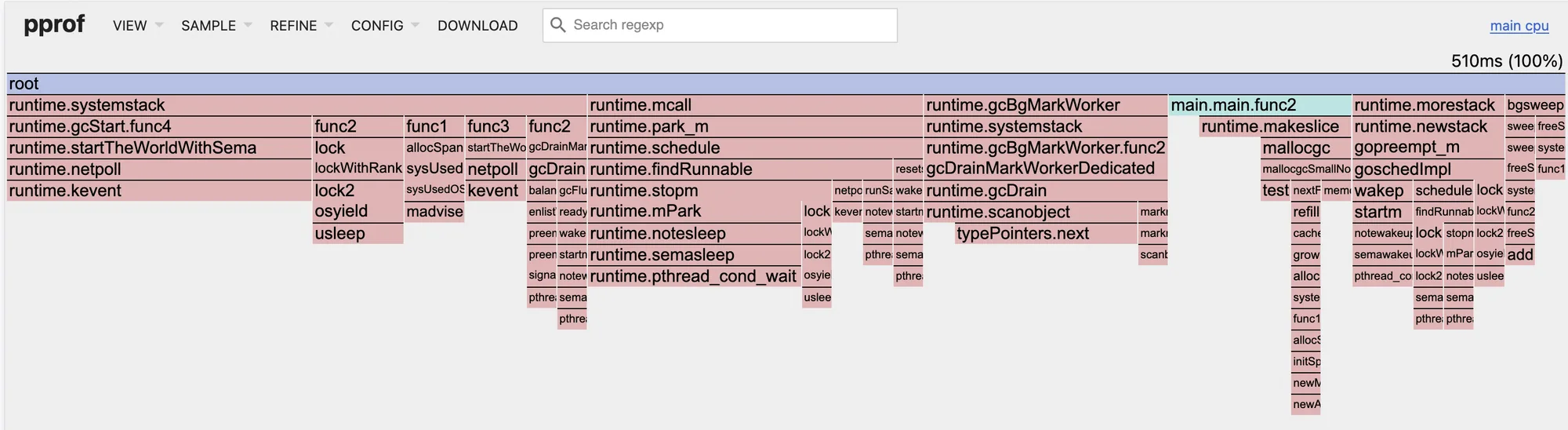
Теперь посмотрим, сколько общего процессорного времени занял GC. В одной вкладке запускаем программу с GODEBUG=gctrace=1:
GODEBUG=gctrace=1 go run gc_visualizer/main.goВ соседнем терминале - pprof:
go tool pprof -seconds 20 -http=:8080И видим, что все семплы на CPU заняли 510ms:
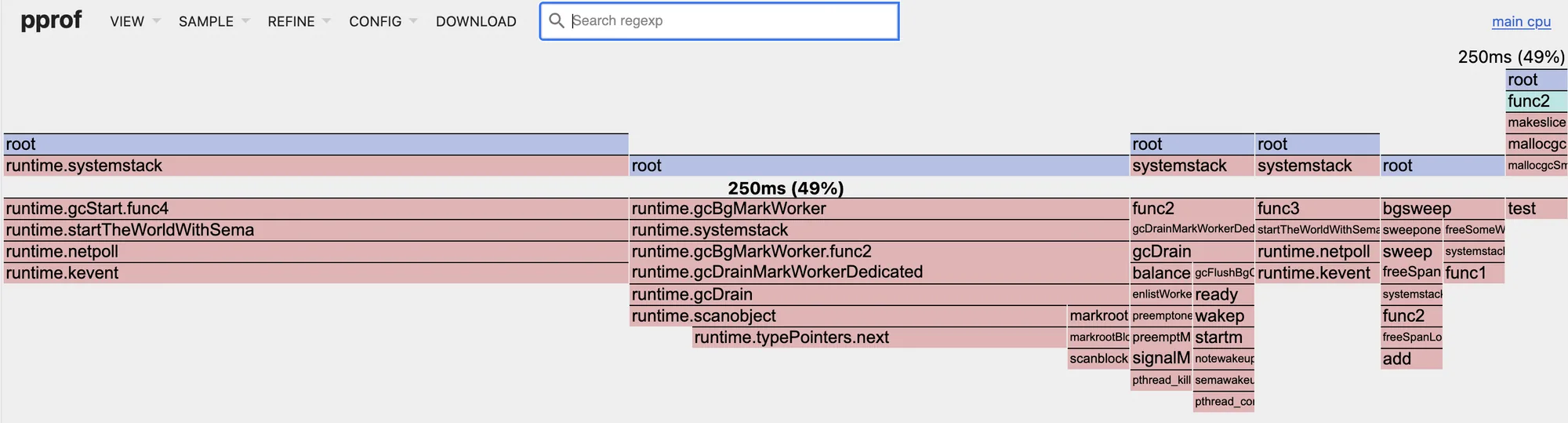
Вот тот же профиль, но отфильтрованный на методы, которые использовал GC:
Теперь посмотрим на код на Rust'е, выполняющий похожую логику:
use std::{thread, time::Duration};
use pprof::ProfilerGuardBuilder;
use pprof::protos::Message; // for write_to_writer()
fn main() {
let guard = ProfilerGuardBuilder::default()
.frequency(100)
.build()
.unwrap();
let mut keep: Vec<Vec<u8>> = Vec::new();
for i in 0..1_000_000u32 {
let buf = vec![0u8; 1024];
if i % 1000 == 0 { keep.push(buf); }
if i % 100_000 == 0 { println!("iter {i}"); thread::sleep(Duration::from_millis(1000)); }
}
println!("done, kept: {}", keep.len());
if let Ok(report) = guard.report().build() {
let mut f = std::fs::File::create("cpu.pb").unwrap();
report.pprof().unwrap().write_to_writer(&mut f).unwrap();
}
}cargo.toml:
[profile.release]
debug = true
[dependencies]
pprof = { version = "0.15", features = ["flamegraph", "protobuf-codec"] }Запускаем:
RUSTFLAGS="-C force-frame-pointers=yes" cargo run --releaseОткрываем через pprof:
go tool pprof -http=:0 ./cpu.pbИ видим, что Rust-профиль показывает 110ms на CPU:
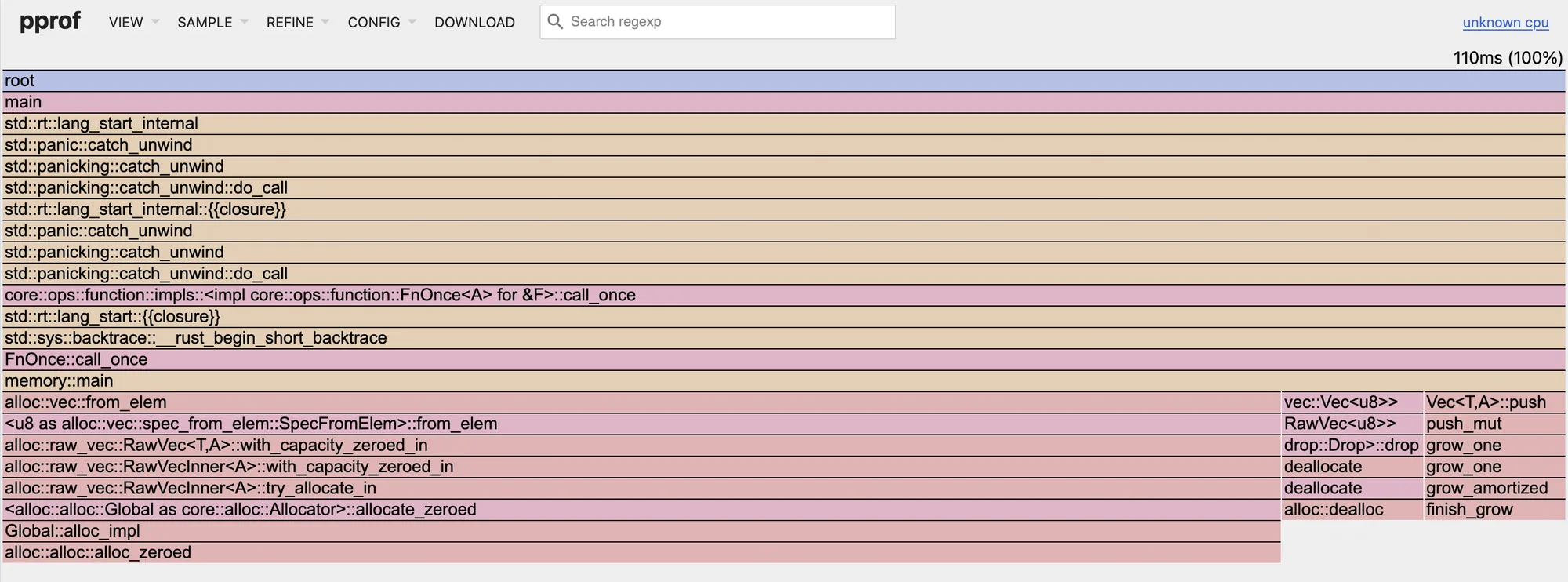
Никаких runtime.gc*, в отличие от Go. Объекты освобождаются сразу, когда выходят из области видимости.
В Rust нет фонового сборщика мусора, поэтому мы не увидим циклов mark/sweep или вызов gcBgMarkWorker. Весь менеджмент памяти — это явные аллокации/деаллокации и вызов drop().
Теперь посмотрим на те же сэмплы, но с фильтром по методам, которые работают с памятью:
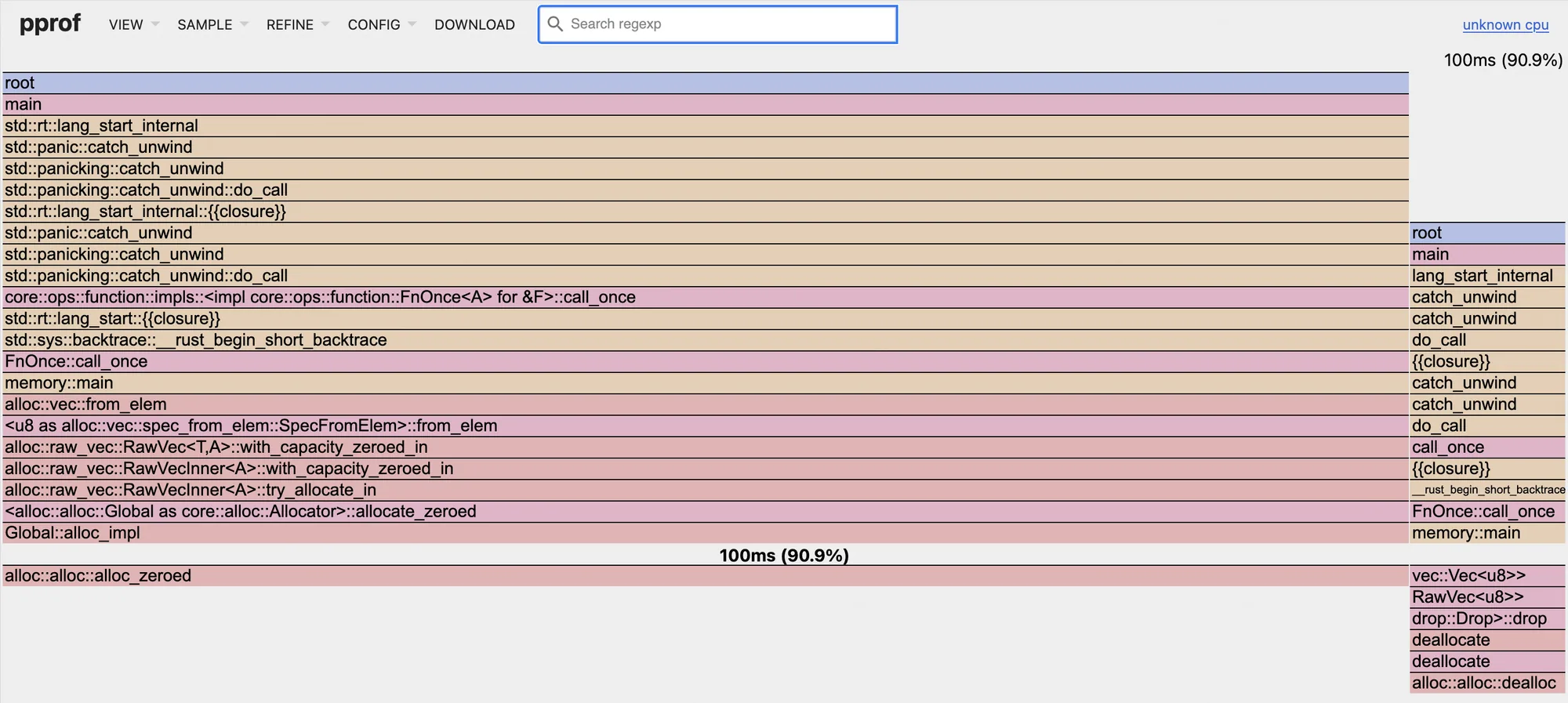
Аллокации заняли суммарно 90% от общего процессорного времени. Но общее время выполнения почти в 5 раз ниже, чем время работы аналогичной программы на Go.
Стоит понимать, что сравнивать такой код в лоб - не совсем корректно. Время работы на CPU может зависеть от множества факторов, сам код тоже работает по-разному. Но общая идея в том, что нужно знать о работе GC в Go и помнить о том, что в случае множества аллокаций на куче - время работы GC и нагрузка на процессор будет существенно выше.
Вывод
Go экономит ваше время сейчас, Rust — время процессора потом. Но помни, что лучший язык — тот, который экономит самый дорогой ресурс в конкретном проекте, и для каждого проекта этот ресурс будет свой.
Не забудь подписаться - достаточно внизу оставить свой email и тебе будут приходить уведомления о новых статьях.
Так же я веду telegram-канал с дайджестом материалов по Go:
https://t.me/the_dev_signalИ авторский телеграм-канал, куда пишу различные заметки, инструменты и делюсь опытом:
https://t.me/junsenior